Fast Logging for HFT In Rust
In this article, we’ll be discussing a fast way of logging in Rust and its application to high-frequency trading. The code presented here solves two problems, one is well-known, the latter less so. It is imperative to avoid using IO operations within the strategy thread, but logging operations can hide a lot of memory operations that should also be avoided. Logging from the strategy is useful for monitoring or debugging purposes. Logging can however be expensive if implemented inefficiently. I have known companies to run two builds in production, one with logging and the other without logging that trades. This set-up avoids any issues with logging affecting the strategies throughput, however, this in my opinion is a fairly extreme solution.
When discussing latency we also need to talk not only about the mean latency but also the full latency distribution. It’s important to be fast, but also to be consistently fast. HFT trading platforms are a form of asynchronous message systems and latency can be measured as the time between an input message such as an orderbook update and an output message such as an order. Message rate tends to be correlated with volume and volume tends to be correlated with market opportunity. It is quite normal for latency to spike when message rates spike. This is why not only the mean latency should be measured but the 99 and the 99.9 percentile latency. What is to be avoided is delaying the sending of orders since the system is stuffed with messages that it cannot process fast enough.
As discussed in the previous article, one of the main advantages of using languages such as C++ or rust because of their lack of garbage collection. Garbage tends to be created when there is a lot of activity and the garbage collectors (GC) make latency non-deterministic since other processes are blocked as it runs. I have not used Java in a long time so if there is now a decent parallel/concurrent GC then please forgive me. Even so, GCs are to be avoided even when using a GC language.
When trying to write efficient code there are a few important general rules. Memory operations tend to be quite expensive compared to arithmetic operations. Many high-frequency trading platforms tend to either not use data structures or to pre-allocate memory on startup. Other operations which are relatively expensive include those associated with IO or locking since those deal with the operating system. The issue with the operating system is not only that operations are relatively slow but because operations need to be synchronised across multiple processes, the latency of the operations is non-deterministic.
Let’s start with a naive implementation of logging.
/* simple logging using println! */
let date = Local::now();
println!("ts: {} volume: {} price: {} flag: {}", date.format("%Y-%m-%d %H:%M:%S"), 100.02, 20000.0, true);
One of the main issues with logging is that this involves a slow IO operation. The simple solution to this is to use asynchronous logging so the IO thread is separated from the strategy thread. This can significantly improve both the strategy latency and also the latency variance. A common implementation of this is to generate a log string and then serialise it to a separate async logging thread. This can be done via a lock-free queue of some sort to avoid the strategy thread needing to wait for locks.
The following is an improved implementation that uses a lock-free queue to communicate between threads.
/* implementation of logging on an asynchronous thread */
use lockfree::channel::spsc::{create, Sender, Receiver};
// set up async logging thread
let (mut sx, mut rx) = create::<String>();
let guard = thread::spawn(move || {
let core_ids = core_affinity::get_core_ids().unwrap();
core_affinity::set_for_current(*core_ids.last().unwrap());
match (rx.recv()){
Ok(msg) => { print("{}", msg); }
Err(e) => { panic!("well this is not good"); }
}
});
// strategy thread
let date = Local::now();
let log_msg = format!("ts: {} volume: {} price: {} flag: {}", date.format("%Y-%m-%d %H:%M:%S"), 100.02, 20000.0, true);
sx.send(log_msg).unwrap(); // should really handle errors
How expensive is the creation of the log string? The answer is a lot. Often timestamps are formatted to date string and the creation of the string itself involves dynamic memory allocation which should be avoided. It would be much better if it was possible to offload not only the IO operations but also the string building to a separate thread. Getting around this cost using an alternative implementation is pretty difficult to achieve in most languages.
A function is needed that takes not only a variable number of parameters but a variable number of parameters of arbitrary type. This is relatively complicated to do in strongly typed languages such as Rust and C++. One solution to this is to use some form of binary serialisation such as bincode, protobuffers or BSON to serialise the arguments to be logged as well as the format string. This is possible, but I don’t think it is the most efficient way to do it. For performance reasons, it would be better if most of this work could be done at compile time to avoid unnecessary memory operations.
Rust provides an alternative and very neat solution to this problem. In Rust closures can be serialised directly and then sent to another thread to be executed. So it is possible to create a closure which creates the log string and then outputs the log string. Instead of anything being executed by the strategy thread the function pointer and arguments are serialised and send via a channel. When this is received by the logging thread the closure can be deseralised and then invoked avoiding the strategy thread from having to do anything.
/* asynchronous execution of a serialised closure */
use lockfree::channel::spsc::{create, Sender, Receiver};
// struct for wrapping the closure so it can be serialised
struct RawFunc { data: Box<dyn Fn() + Send + 'static> }
impl RawFunc {
fn new<T>(data: T) -> RawFunc
where T: Fn() + Send + 'static,
{ return RawFunc { data: Box::new(data) }; }
fn invoke(self) { (self.data)() }
}
// create async thread to execute logging closure
let (mut sx, mut rx) = create::<RawFunc>(); // lock free channel
let guard = thread::spawn(move | | {
let core_ids = core_affinity::get_core_ids().unwrap();
core_affinity::set_for_current(*core_ids.last().unwrap());
match (rx.recv()){
Ok(msg) => { output.invoke(); }
Err(e) => { panic!("well this is not good"); }
}
});
// strategy thread
let date = Local::now(); // the timestamp should be from the strategy thread
sx.send(RawFunc::new(move || {
println!("ts: {} volume: {} price: {} flag: {}", date.format("%Y-%m-%d %H:%M:%S"), 100.02, 20000.0, true);
})).unwrap(); // should really handle errors
The relative performance of the three solutions on my local machine are logging directly takes on average 1769 nanoseconds, creation of the log string and serialising it takes roughly 1189 nanoseconds on average, and the solution to serialise the closure takes on average 120 nanoseconds. I think a reasonable target latency of a strategy should be in the single-digit microseconds. This serialised closure implementation of logging means this latency target is possible while still being able to log from the strategy thread. The real benefit of using the closures is that it doesn’t require any string or memory operations so there is also almost no impact in the 99% tail of the latency distribution. If we examine the latency distribution of each of these implementations this is easy to see. The closure version has much better behaviour.
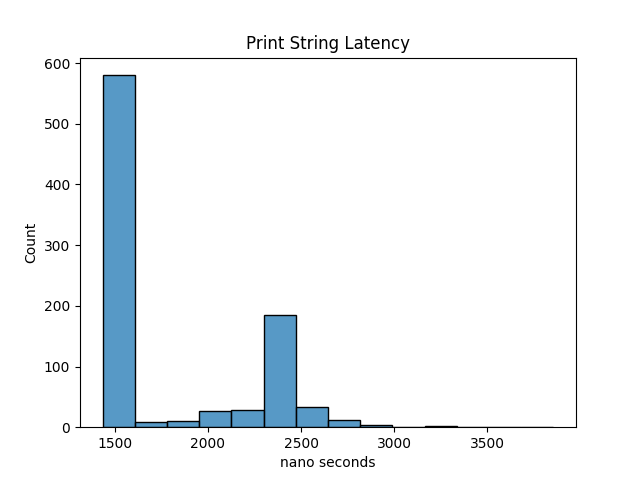
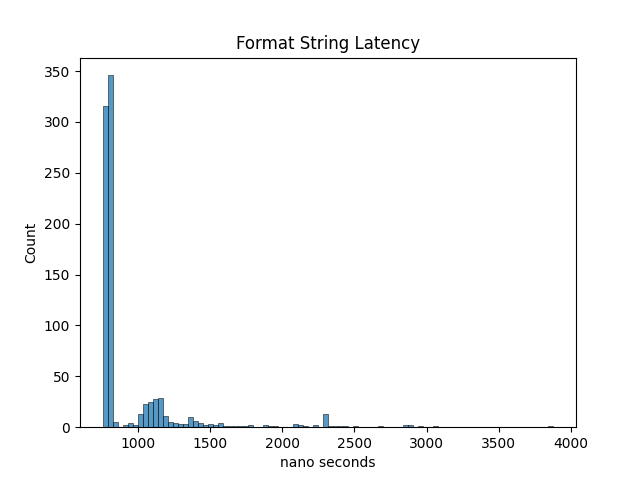
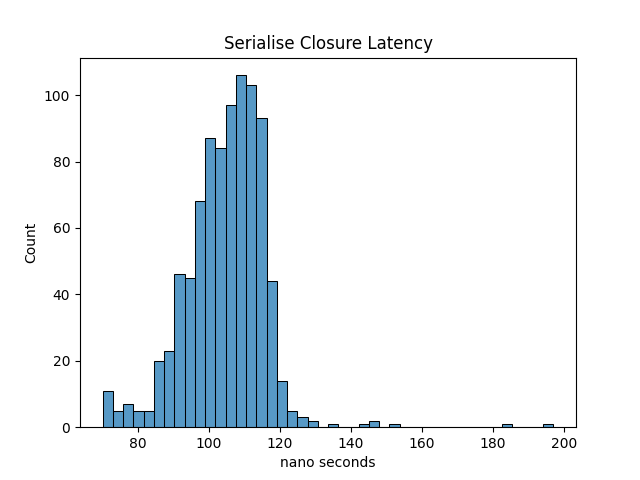
When looking at the graphs the real improvement with regard to using serialised closures can be seen. Not only is the closure method faster on average but its latency distribution is much more predictable. I was somewhat surprised that the difference in results for string serialisation is so wild, but I put that down to the date formatting and string building.
It is possible to implement something similar in other languages. C++ has lambdas and I think these can be serialised. What I like about Rust is that the majority of the complexity is taken care of by the compiler for very little performance cost. You also don’t have to worry about concurrency issues since the compiler also makes sure that ownership is transferred to the logging thread. The more I learn about Rust the more I like its productivity as a function of programmer hours. I think this article is a cool example of that.