Message Arrival Rates and Latency
There is a common debate when people are discussing code optimisation that relates to how fast code needs to be.
A recent Twitter post about parsing binance BBA messages stated processing times of around 200ns. This is, in my admission, is very fast.
To put it into perspective, Serde is a common rust deserialization library and is incredibly easy to use.
It is however, a lot slower than the optimised alternative taking around 2-3 micro seconds to do the same work.
But who cares if your code takes 2 micro seconds longer to process a message?
Is this going to make a huge difference to your pnl give that network jitter can be measured in milliseconds?
The answer is yes, and maybe not for the reason you think.
Tick to Trade
Tick to trade (t2t) is measured as the time taken to receive a message and to generate some form of exchange api call (place/cancel/amend).
This processing time can be measured either in software or at the network interface card.
Most trading systems are event/message engines and at their core, the strategy is single threaded.
If you are running a latency sensitive strategy, having a low tick to trade means an order get to the exchange sooner and has a higher chance of being filled.
For strategies like market making it is still really important to be fast, just for different reasons. The simplest reason is that if there is a signal that requires cancelling orders, we would like to do this as quickly as possible.
The main issue is related to the statistical distribution of message arrival rates. Financial market data are known to be hetero-skedastic. That is just a fancy way to say markets occasionally go bananas. When market making you might be monitoring many different markets and instruments at the same time. It would be much simpler if data arrived at regular intervals and everyone was given enough time to make decisions. This is however not the world we live in.
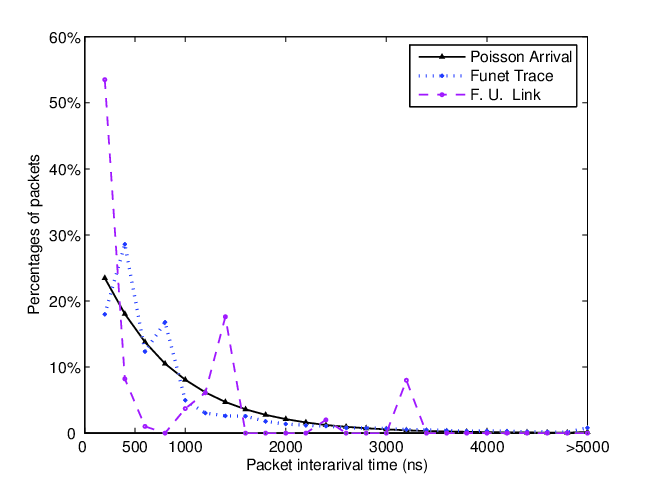
The image above is from a paper about queue behaviour and packet delays. It is the closest thing I could find that describes the problem. The time between messages is not uniform and it tends to follow an exponential distribution. The resulting effect is, when it rains, it pours and you will get a lot of messages all at once.
Where 2t2 latency becomes a problem is due to the limits of throughput. It is possible to get 100s or 1000s of messages in a very short space of time. Maybe (and this is likely) the message that triggers a trade is the last one in the queue. So if your per message processing time is 100 mics, during a burst of 1000 messages, you will take 100 milliseconds before you send a trade. So you think you have a t2t of 100 mics, but in actuality, the trade was delayed much longer than you would expect.
Analysis
I was interested to see the effect of this on real world crypto data. In reality, for a production system, the actual t2t for orders should be monitored and measured. This analysis is indicative of how the delay distribution changes as a function of message processing time. It also gives an idea of what kind of processing times you should be aiming for.
The best method to measure the impact of delays is to tag market data with an id. Exchange api calls (place/cancel/amend) can then be tagged with the same id of the market data that triggered the api call. If there are delays due to the queue being saturated, it is possible to detect it. This can be a little tricky to do as it requires tagging messages on the network interface card (NIC). If you are able to do this, it is worth it as it is the only way to truly know if the websocket is not processed quickly enough.
The data is from 12 liquid swap and spot crypto pairs on 4 exchanges. The data was collected on May 1st 2024 and the message count was 175,001,142. If all these messages were uniformly spaced in a day, there will be approximately 494.3 microseconds between each message. This is not a lot of time, but it should be more than enough.
Looking at the actual message rates, the data is much more clustered.
largest number of messages per micro second: 4
largest number of messages per milli second: 656
largest number of messages per second: 38,046
There are many times we receive over 650 messages in a single millisecond. If the system took 100 mics to process a single message, it would only be able to process 10 of them in this time. This likely, will very quickly become a problem and cause the queue to get backed up.
If you assume a fixed t2t of x nano seconds how much delay is there between getting the message and processing it?
now = 0
delays = []
for i in timestamps:
if i > now:
now = i
delays.append(now - i)
now += offset
I was actually quite surprised by the results. In the case where each message takes 100 micros each to process, 65% of messages will have some delay.
| t2t | Num Delayed | Ratio Delayed |
|---|---|---|
| 1 micro | 1,016,411 | 0.58% |
| 5 micros | 18,935,745 | 10.82% |
| 10 micros | 62,505,279 | 35.72% |
| 100 micros | 114,178,670 | 65.24% |
As a rule of thumb, it is better to have an internal latency below 10 micro seconds. I was surprised that even 10 micro second processing times mean that 35% of messages experience some delay. The distribution of delays can be seen in the table below.
| t2t | 90% | 95% | 99% | 99.9% | 99.99% |
|---|---|---|---|---|---|
| 1 micro | 0.0 mics | 0.0 mics | 0.0 mics | 0.82 mics | 0.99 mics |
| 5 micros | 0.34 mics | 3.82 mics | 34.81 mics | 319.34 mics | 1.217 ms |
| 10 micros | 35.69 mics | 75.52 mics | 234.32 mics | 1.28 ms | 11.11 ms |
| 100 micros | 10.52 ms | 32.84 ms | 4.14 s | 26.38 s | 27.22 s |
I also did an analysis assuming a 2t2 of 1 milli-second. The delays were so long I think it is pointless to report. Languages like python are thus not really viable solution for market making a large number of liquid assets purely due to data volumes.
Problem => Solution
So if this is a problem, what are the potential fixes?
- Be faster
- Triage and conflate messages. This is only really possible with order book data using seq locks
- Subscribe to less data
- Parallelize parts of the pipeline that are pre strategy/risk engine
The main thing is to be aware of the potential problems and be able to measure its impact on your system and specific use case.
I just hope this lays to rest the discussion that being fast is not important unless you’re running a latency arbitrage strategy.
Data tends to come in huge bursts, and the last thing you want is to be stuck working through a backlog when you should be sending orders.
Possible Analysis Issues
I had limited time to do the analysis, I can see some potential weaknesses if you want to be pedantic. I do not think the points below change the over all conclusion.
- Trading systems are distributed systems to the processing is done over multiple cores.
- The timestamps of the collected data is based on the systems ability to read from the ws and timestamp it. This takes about 350 ns so it is possible that the recorded data contains its own delays all be it small.
- Paths through a system’s logic are varied. Each path will have its own t2t. Assuming a single constant value is simplistic.
- I only looked at a single day of data.
Conclusion
- Crypto websocket feeds produce a lot of data.
- That data comes in very concentrated bursts.
- You probably want to aim to be able to read and process from a websocket in < 5 microseconds to avoid delays > 1 ms at the 99.99 percentile.
- Reading from websocket, parsing, timestamping and placing on a channel is possible in sub 1 micro in rust.
The next time someone asks, “why bother saving 1 micro second?” You can point them to this article. I know I will be…